Nvidia DGX Spark
Cómo creamos un sistema RAG de producción en DGX Spark en Costa Rica (y cuánto costó)
Un análisis en profundidad de la implementación de GPT-OSS en NVIDIA DGX Spark, la optimización de Ollama para la inferencia en producción y la transmisión de respuestas a través de Fastly, todo ello desde un centro de datos latinoamericano que presta servicio a clientes nearshore y regionales.
El problema que estábamos resolviendo
Una empresa latinoamericana acudió a nosotros con un reto concreto: necesitaban una inferencia de generación aumentada por la recuperación (RAG) apta para producción para consultas en español, con tres requisitos imprescindibles.
En primer lugar, la residencia de los datos. Su postura normativa y los contratos con los clientes impedían que los datos de las consultas salieran de la región. Los proveedores de API en la nube —aunque cumplieran técnicamente con la normativa— resultaban difíciles de vender a nivel interno por motivos políticos.
En segundo lugar, unos costes predecibles a gran escala. El volumen de consultas previsto hacía que la tarificación por token de la API resultara muy costosa. Un cálculo aproximado reveló que su gasto anual en API comerciales de modelos de lenguaje grande (LLM) superaría el coste de capital de adquirir hardware de inferencia dedicado en unos nueve meses.
En tercer lugar, la latencia. Sus usuarios esperaban tiempos de respuesta similares a los de una conversación. El recorrido de ida y vuelta hasta los puntos finales de la costa este de EE. UU. o de Europa añadía una sobrecarga de red suficiente como para deteriorar la experiencia, especialmente en el caso de las respuestas de tokens en streaming, donde el tiempo hasta el primer token es lo que los usuarios perciben realmente.
La solución que elegimos: un NVIDIA DGX Spark que ejecuta modelos GPT-OSS a través de Ollama, respaldado por un almacén de vectores y una capa de orquestación, con Fastly en el perímetro gestionando la transmisión de eventos enviados por el servidor (SSE). Implementado en nuestro centro de datos de Costa Rica, conectado directamente a través del AS52423.
En este artículo se analizan la arquitectura, las optimizaciones que realmente marcaron la diferencia y los aspectos económicos reales del funcionamiento de una infraestructura de IA en producción en América Latina en 2026.
¿Por qué una solución local?, ¿por qué DGX Spark?, ¿por qué Costa Rica?
Antes de entrar en detalles técnicos, es importante entender el «porqué», ya que la arquitectura solo tiene sentido si se comprende el marco de decisión que hay detrás.
Comparación de precios
Con el volumen de consultas que nos habíamos fijado como objetivo, los cálculos económicos quedaban más o menos así:
| Opción | Coste mensual aproximado | Notas |
|---|---|---|
| API comercial (tipo GPT-4) | entre 18 000 y 25 000 dólares | Se adapta linealmente al volumen; sin retención de datos |
| Inferencia con GPU en la nube (H100, bajo demanda) | entre 12 000 y 18 000 dólares | La cuestión de la residencia de los datos sigue sin resolverse; la salida de datos conlleva un coste adicional |
| Inferencia con GPU en la nube (reservado) | entre 7.000 y 10.000 dólares | Mejora económica, pero aún fuera de la región |
| DGX Spark | 1.670-1.900 dólares | Incluye un firewall dedicado y un enlace de subida ilimitado de 500 Mbps |
En el caso de este perfil de cliente, el hardware propio ubicado en la región resultaba varias veces más barato que cualquier opción en la nube una vez alcanzado el volumen de equilibrio. El umbral de rentabilidad frente a una GPU reservada en la nube se situaba aproximadamente en el séptimo mes.
¿Por qué precisamente el DGX Spark?
DGX Spark es la estación de trabajo compacta de IA de NVIDIA basada en el superchip GB10 Grace Blackwell. Está diseñada para el desarrollo local de modelos y la inferencia a una escala significativa: cuenta con 128 GB de memoria unificada, ancho de banda suficiente para ejecutar cómodamente modelos abiertos de tamaño medio y un formato que cabe en un rack estándar sin las exigencias de alimentación y refrigeración de un servidor H100.
Para este caso de uso —la inferencia en producción con modelos de peso abierto en el rango de 20 000 a 70 000 millones de parámetros— resulta ideal. No se trata de entrenar modelos base, pero cumple con creces a la hora de ofrecer a los usuarios reales modelos cuantificados de tipo GPT-OSS, Llama y Mistral.
¿Por qué Costa Rica?
Tres razones, y todas ellas son más prácticas que patrióticas.
Latencia. Para los usuarios de Centroamérica y la mitad norte de Sudamérica, Costa Rica supera a Miami, Dallas y São Paulo en cuanto al tiempo de ida y vuelta en la mayoría de los casos. Para los clientes nearshore de EE. UU. que operan en los husos horarios del centro o del este, la diferencia de latencia con respecto a la costa este de EE. UU. es mínima, a menudo inferior a 40 ms.
Interconexión entre pares. Nuestra posición en el AS52423 nos proporciona interconexiones directas que resultan fundamentales para este tipo de carga de trabajo. La transmisión SSE es más sensible a la fluctuación y a la pérdida de paquetes que al ancho de banda bruto, y unas rutas de interconexión entre pares sin interferencias marcan una diferencia apreciable en la calidad de respuesta percibida.
Adecuación normativa. Para las empresas de Latinoamérica que deben cumplir requisitos de residencia de datos, el alojamiento dentro de la región a través de una entidad local resuelve problemas que ninguna documentación de cumplimiento del proveedor de servicios en la nube puede resolver por completo.
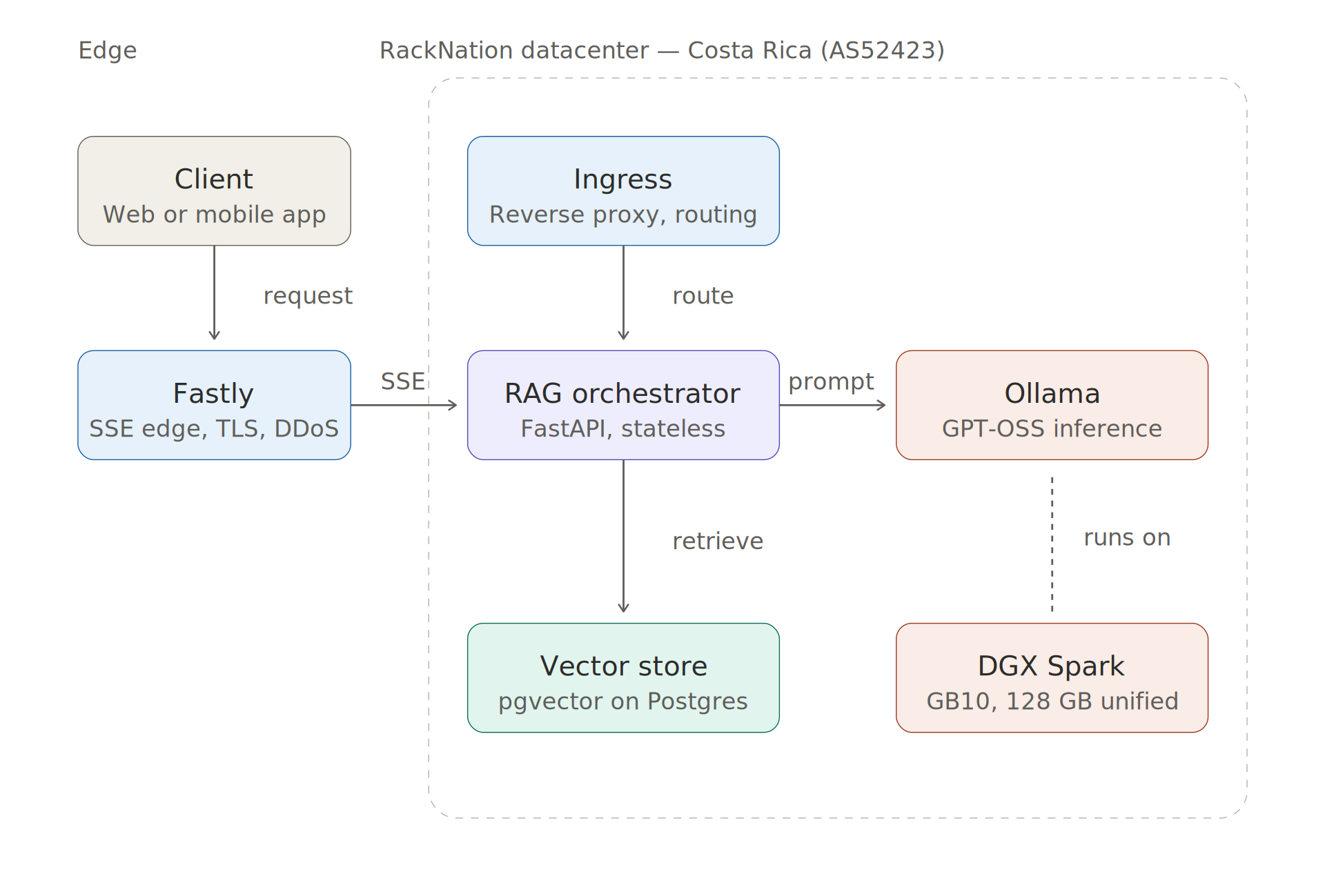
La arquitectura
«Arquitectura de extremo a extremo: cliente → Fastly Edge (SSE) → RackNation Ingress → RAG Orchestrator → Ollama en DGX Spark + almacén pgvector»
El flujo es sencillo: una consulta de usuario entra a través de Fastly en el perímetro, llega a nuestra capa de entrada en Costa Rica, es gestionada por un orquestador sin estado que realiza la recuperación de vectores y la construcción de la respuesta, y luego envía una respuesta desde Ollama, que se ejecuta en DGX Spark, de vuelta al cliente a través de SSE.
Algunas notas sobre las opciones.
Fastly en el perímetro. Utilizamos Fastly para la terminación SSL, la absorción de ataques DDoS y, lo que es más importante, la transmisión SSE. Fastly gestiona bien las conexiones de transmisión de larga duración, y su presencia en el perímetro hace que el primer protocolo de enlace TCP se establezca cerca del usuario, incluso cuando el servidor de inferencia se encuentra en Costa Rica.
El orquestador. Un servicio ligero en Python (FastAPI) que recibe las consultas de los usuarios, realiza la recuperación de vectores, genera la indicación con el contexto recuperado y transmite la respuesta de Ollama al cliente. Sin estado, escalable horizontalmente, se ejecuta en su propia máquina virtual en nuestro clúster Proxmox.
Almacén de vectores. Optamos por pgvector en una instancia dedicada de Postgres. Dado el tamaño del corpus de este cliente (menos de 10 millones de representaciones), resulta más que suficiente, es más sencillo de gestionar que ejecutar una base de datos de vectores dedicada y permite aprovechar los conocimientos que ya tienen sobre Postgres.
Ollama en DGX Spark. Aquí es donde hemos dedicado más tiempo y donde reside lo más interesante desde el punto de vista técnico.
¿Por qué elegir Ollama en lugar de vLLM, TGI o llama.cpp directamente?
Los evaluamos todos. La decisión se basó en tres factores:
- Facilidad de uso. La gestión de modelos de Ollama —extraer, intercambiar y mantener activos varios modelos— es realmente buena. En un entorno de producción en el que de vez en cuando es necesario realizar pruebas A/B con los modelos o aplicar actualizaciones hacia adelante o hacia atrás, esto es importante.
- Un rendimiento más que aceptable. Para nuestro perfil de concurrencia (decenas de usuarios simultáneos, no cientos), el rendimiento de Ollama se sitúa muy cerca del de vLLM. La diferencia se reduce aún más una vez que se optimiza.
- Ocupa poco espacio. Funciona perfectamente con systemd, ofrece API HTTP claras y no hace falta ser un experto en CUDA para utilizarlo.
vLLM habría sido la opción adecuada si hubiéramos tenido que atender cientos de solicitudes simultáneas con el máximo número de tokens por segundo. Para esta carga de trabajo, las ventajas operativas se decantaban a favor de Ollama.
Optimización del rendimiento de Ollama: qué fue lo que realmente marcó la diferencia
Esta es la sección que la mayoría de los lectores estaban esperando. Esto es lo que hemos aprendido al pasar de la configuración predeterminada de Ollama a un rendimiento listo para producción en DGX Spark.
Situación inicial (antes de la optimización)
Ejecución de GPT-OSS con la configuración predeterminada de Ollama, en una sola unidad DGX Spark, sin ajustes:
- Tokens/segundo (solicitud única): ~42
- Tiempo hasta el primer token (P50): 780 ms
- Tiempo hasta el primer token (P95): 1 400 ms
- Solicitudes simultáneas antes de la degradación: 3
- Utilización de la memoria de la GPU: ~58 %
Es una solución válida, pero no está lista para la concurrencia prevista.
Optimización 1: Estrategia de carga del modelo
Por defecto, Ollama descarga un modelo de la VRAM tras unos minutos de inactividad. Para un sistema RAG con picos de tráfico, esto resulta desastroso: cada usuario cuya consulta llegue durante un periodo de arranque en frío tarda entre 8 y 15 segundos en cargar el modelo.
La solución: OLLAMA_KEEP_ALIVE=-1 para el modelo de producción, junto con una gestión cuidadosa de la memoria, de modo que sepamos exactamente qué cabe en la VRAM al mismo tiempo.
Mantenemos el modelo GPT-OSS principal siempre activo, además de un modelo más pequeño (para la clasificación de consultas y el filtrado de seguridad) que también está siempre cargado. Cualquier modelo experimental o de reserva se carga de forma diferida cuando es necesario.
Impacto: Se ha eliminado por completo la latencia de arranque en frío del modelo principal. El tiempo hasta el primer token (P95) se ha reducido de 1.400 ms a menos de 500 ms.
Optimización 2: Concurrencia y procesamiento por lotes
De Ollama OLLAMA_NUM_PARALLEL Este parámetro determina el número de solicitudes que se procesan simultáneamente por cada modelo. El valor predeterminado es conservador.
Hemos ajustado esto basándonos en el margen real de VRAM y en el comportamiento medido. Para GPT-OSS en nuestra configuración DGX Spark, OLLAMA_NUM_PARALLEL=4 Resultó ser el punto óptimo: unos valores más altos provocaban sobrecarga de la VRAM y, en ocasiones, el sistema se bloqueaba por falta de memoria bajo una carga sostenida; unos valores más bajos, por su parte, impedían alcanzar el máximo rendimiento.
Además de esto, OLLAMA_MAX_LOADED_MODELS=2 evita que Ollama intente cargar modelos adicionales cuando la memoria VRAM es escasa.
Impacto: La capacidad de solicitudes simultáneas pasó de 3 a 11 antes de que se produjera un aumento de la latencia. El número total de tokens por segundo bajo carga simultánea se triplicó aproximadamente.
Optimización 3: Disciplina en el uso de las ventanas de contexto
Esto no tiene tanto que ver con Ollama como con la forma en que elaboramos las indicaciones. Las implementaciones ingenuas de RAG incluyen todo el contexto recuperado posible en cada indicación, partiendo de la teoría de que «cuanto más contexto, mejores respuestas».
En la práctica, a partir de cierto punto, un mayor contexto implica una inferencia más lenta y respuestas de menor calidad (el modelo se distrae con fragmentos de relevancia marginal).
Hemos ajustado nuestra recuperación para que devuelva los k fragmentos principales, donde k es un valor dinámico que depende de las puntuaciones de relevancia de los fragmentos —por lo general, entre 4 y 8 fragmentos, en lugar de un número fijo de 20—. En combinación con una deduplicación agresiva de fragmentos en la capa de recuperación, la longitud media de las indicaciones se redujo en aproximadamente un 40 %.
Impacto: La mediana de tokens por segundo pasó de 42 a 67. La calidad de las respuestas, medida mediante una evaluación humana en un conjunto de prueba independiente, mejoró ligeramente.
Optimización 4: Elección de la cuantificación
GPT-OSS está disponible en varios niveles de cuantificación. Hemos evaluado Q4_K_M, Q5_K_M, Q6_K y Q8_0 comparándolos con un conjunto de referencia de consultas representativas cuyos resultados han sido evaluados por personas.
Conclusión: Q5_K_M resultó ser el mejor equilibrio para esta carga de trabajo. Q4_K_M fue notablemente más rápido, pero generó un texto en español con sutiles errores gramaticales que los revisores humanos señalaron. Q8_0 ofreció una mayor calidad, pero la pérdida de velocidad no se vio compensada por una mejora en la calidad que nuestros usuarios pudieran percibir.
Este tipo de conclusiones solo se obtienen realizando pruebas comparativas con tu propio corpus y tu propio idioma. No des por sentado que las pruebas comparativas que se encuentran en Internet se aplican a tu caso concreto, sobre todo en el caso de implementaciones en idiomas distintos del inglés.
Lo que no funcionó
Por completar, algunas cosas que probamos y que no dieron resultado:
- Ejecutar dos instancias de Ollama en el mismo DGX Spark para particionar los modelos. No sirve de nada: la programación interna de Ollama ya gestiona esto mejor que la partición a nivel de proceso.
- Ajuste de Flash Attention. No resulta significativo para nuestra carga de trabajo a este nivel de concurrencia; las mejoras eran insignificantes.
- Captura personalizada de gráficos CUDA. Demasiada complejidad operativa para una ganancia demasiado escasa en el contexto de Ollama.
Tras la optimización
| Sistema métrico | Situación inicial | Optimizado | Mejora |
|---|---|---|---|
| Tokens por segundo (solicitud única) | 42 | 67 | +60% |
| Tiempo hasta la primera muestra (P50) | 780 ms | 210 ms | -73% |
| Tiempo hasta el primer token (P95) | 1 400 ms | 480 ms | -66% |
| Solicitudes simultáneas antes de la degradación | 3 | 11 | +267% |
| Utilización de la memoria de la GPU | 58% | 81% | Mejor aprovechamiento |
Fastly y SSE Streaming: la capa periférica
La transmisión de respuestas de modelos de lenguaje grande (LLM) a través de HTTP es un problema resuelto en principio, pero complicado en la práctica. Los eventos enviados por el servidor (Server-Sent Events) son la solución ideal: son más sencillos que los WebSockets, funcionan a través de la infraestructura HTTP estándar y no requieren complicadas actualizaciones de protocolo.
Los problemas menos evidentes con los que nos topamos:
Se está cargando. El comportamiento predeterminado de Fastly para algunos tipos de contenido es almacenar las respuestas en el búfer antes de su entrega. En el caso de SSE, debes asegurarte de que el Tipo de contenido: text/event-stream el encabezado se conserva de principio a fin y que el VCL de Fastly no activa las heurísticas de almacenamiento en búfer. Hemos desactivado explícitamente beresp.do_stream = false (es decir, activar la transmisión) para el punto final de inferencia.
Tiempos muertos. Los tiempos de espera predeterminados son demasiado estrictos para la transmisión de modelos de lenguaje grande (LLM), donde una respuesta puede tardar perfectamente más de 30 segundos en completarse. Hemos aumentado tiempo de espera del primer byte y tiempo_de_espera_entre_bytes en la capa de Fastly y los comparó en el origen.
Detección de inactividad y mantenimiento de la conexión. Algunos servidores proxy intermedios y los NAT de los operadores de telefonía móvil cortan las conexiones que consideran inactivas, incluso cuando hay flujo de datos SSE. Enviamos comentarios SSE periódicos (: keepalive\n\n) cada 15 segundos para mantener el conducto abierto. Un seguro muy económico.
Señalización de errores. SSE no dispone de señalización nativa de errores una vez que se inicia el flujo. Hemos adoptado la convención de enviar un evento final con evento: error y una carga útil JSON estructurada en caso de que surja algún problema durante la transmisión, de modo que el cliente pueda mostrar mensajes de error claros en lugar de limitarse a ver cómo se cierra la conexión.
Qué supervisamos
La observabilidad es más importante en la inferencia de modelos de lenguaje grande (LLM) que en las cargas de trabajo web tradicionales, ya que los modos de fallo son más sutiles. Un punto final lento que sigue devolviendo resultados es más difícil de detectar que un error 500.
Las métricas que realmente seguimos:
- Tiempo hasta la aparición del primer token. P50, P95, P99. Esto es lo que los usuarios perciben como «rápido» o «lento».
- Tokens por segundo bajo carga. Medido a nivel de Ollama, agrupado por concurrencia.
- Utilización de la GPU y margen de VRAM. Si el margen de VRAM cae por debajo del 10 %, algo está a punto de fallar.
- Profundidad de la cola en Ollama. Si las solicitudes se acumulan en la cola, la latencia se ve afectada antes que el rendimiento.
- Latencia de recuperación. Tiempos de consulta de pgvector, independientemente de la inferencia.
- Duración total de la solicitud por componente. Desglosada en recuperación, generación de sugerencias, inferencia y transmisión. De este modo, queda claro a qué capa hay que atribuir la culpa cuando el sistema se ralentiza.
Genera alertas cuando la latencia P95 se mantiene por encima del umbral, el margen de VRAM está por debajo del umbral y ante cualquier reinicio de Ollama. Aprendimos a la fuerza la importancia de alertar ante los reinicios de Ollama: los reinicios silenciosos habían estado ocultando una fuga de memoria intermitente durante una semana antes de que nos diéramos cuenta.
La economía, sinceramente
Para este cliente, con un volumen estable, el coste por millón de tokens asciende aproximadamente a entre 0,80 y 1,20 dólares, incluyendo el hardware amortizado, la energía, la refrigeración y la coubicación. Esto contrasta con los aproximadamente 15-30 dólares por millón de tokens que cuestan las API comerciales para una clase de modelo comparable, y con los aproximadamente 3-6 dólares por millón de tokens que cuesta una GPU reservada en la nube.
El cálculo del umbral de rentabilidad:
- Si tu volumen es inferior a unos 50 millones de tokens al mes, las API comerciales son casi con toda seguridad más económicas que adquirir hardware propio, una vez que se tienen en cuenta los gastos operativos.
- Entre 50 y 200 millones de tokens al mes; depende en gran medida de tus requisitos de latencia y cumplimiento normativo. Una GPU en la nube reservada suele ser la solución adecuada.
- A partir de unos 200 millones de tokens al mes, cuando existen requisitos de residencia de datos en la región, el hardware propio ubicado en la región empieza a ser la opción más ventajosa tanto en términos de coste como de latencia.
Esto no es una regla universal: los resultados varían en función del tamaño del modelo, los patrones de consulta y el peso que le des a los factores ajenos al coste. Pero el principio se mantiene: calcula tu volumen real, sé sincero con respecto a tus requisitos de cumplimiento normativo y haz números antes de dar por sentado que la nube siempre es más barata.
Lo que haríamos de otra manera
En un espíritu de sincera reflexión:
Al principio, diseñamos la capa de orquestación de forma excesivamente compleja. La primera versión contaba con interruptores de circuito muy elaborados, lógica de reintentos y un sistema de respaldo multimodelo. En producción, casi nada de eso se activó. En la segunda versión, la simplificamos considerablemente.
Subestimamos la inversión necesaria en observabilidad. Pensábamos que las herramientas estándar de APM serían suficientes. Pero no fue así: las cargas de trabajo de los modelos de lenguaje grande (LLM) requieren una instrumentación personalizada para resultar útiles, y la implementamos a posteriori en lugar de hacerlo de forma proactiva.
Deberíamos haber comparado las cuantificaciones antes. Pasamos semanas optimizando Q8_0 antes de darnos cuenta de que Q5_K_M era el mejor punto de funcionamiento. Empieza por comparar las cuantificaciones y luego optimiza.
Planificar la capacidad para un tráfico con picos es más complicado de lo que parece. Nuestro modelo de capacidad inicial partía de una carga uniforme. El tráfico real presenta picos, y la capacidad de solicitudes simultáneas de DGX Spark está limitada por la VRAM, no por la potencia de cálculo. Ahora asignamos recursos con un margen mayor del que sugerirían los cálculos puros de rendimiento.
Cuándo tiene sentido esta arquitectura
Si estás valorando la posibilidad de desarrollar algo similar, la respuesta sincera es: depende de tu escala, de tu nivel de cumplimiento normativo y de tus requisitos de latencia.
Esta arquitectura resulta adecuada cuando:
- Estás procesando suficientes tokens al mes como para justificar el uso de hardware dedicado (por lo general, más de unos 100 millones de tokens al mes, dependiendo de la clase del modelo)
- Tienes requisitos regionales de residencia de datos o de cumplimiento normativo que dificultan el uso de las API en la nube
- Tus usuarios se concentran en América Latina, o bien gestionas cargas de trabajo cercanas a EE. UU. en las que el perfil de latencia de Costa Rica resulta útil
- Prefieres unos costes predecibles en lugar de una tarifa por token que aumente a medida que crece el éxito
No es la opción adecuada si:
- Necesitas las capacidades de los modelos de vanguardia (GPT-4.5, Claude Opus, Gemini Ultra y similares); los modelos abiertos aún no están a la altura en ese aspecto
- Tu volumen es lo suficientemente bajo como para que los precios de la API sean realmente más baratos
- Si necesitas dar servicio a cientos de usuarios simultáneos por GPU, te conviene un perfil de hardware diferente y probablemente un vLLM en lugar de Ollama
- Tu equipo no dispone de la capacidad operativa necesaria para gestionar la infraestructura de inferencia, o no desea desarrollarla
Ponerse en contacto
Si estás evaluando una infraestructura de IA en producción para Latinoamérica o una implementación nearshore —ya sea mediante coubicación para tu propio hardware de GPU, inferencia gestionada en DGX Spark como la implementación que se describe aquí, o asesoramiento sobre la arquitectura—, estaremos encantados de hablar contigo.
RackNation opera desde Costa Rica (AS52423) y cuenta con interconexión directa, una capacidad significativa de GPU y un equipo que realmente ha gestionado esta infraestructura en entorno de producción. Puedes ponerte en contacto con nosotros en [email protected] o obtener más información sobre nuestros servicios de infraestructura de IA en https://www.racknation.cr/private-ai-as-a-service.